Using EPM Groovy, I was able to transform a >600 MB data file with 34 columns and more than 1 million rows in under 35 seconds (only transformation). Let’s explore how Server-side EPM Automate, CSV Iterator, and CSV Writer may be used to modify a huge data management file. The data file transformation is carried out from a Calculation Manager rule; no third party tools are used.
I’m sure there are numerous ways to use Groovy to complete a task. Consequently, there will be more ways – easier ways and harder ways – to accomplish the same thing. The goal is to explain that this is a feasible option for all of us.
Steps I followed:
- Copy the data management file to Inbox/Outbox directory
- Read the file’s contents using the CSV Iterator function
- Using CSV Writer, transform the records and write those to a new file.
Copy the data management file to Inbox/Outbox directory
We are doing the step because CSV Iterator only accesses Inbox and Outbox explorer’s files. We are getting a File I/O error when using a file name with the data management directory
CopyFileFromInstance is a command that we use in Server Side EPM Automate. By providing identical URLs for the source and target instance, we can copy files between directories in the same instance.
Read Contents of the file using CSV Iterator function
We use the csvIterator to read each line from the data file. It makes no difference if the file is space separated, tab separated, or comma separated. The CSV Iterator allows us to parse any text file by passing the separator character as a parameter.
Transform the records and write to a new file using CSVWriter
For this explanation, I’ve used a simple custom mapping. I want to write ‘Working’ in my first column, change the second column with the values “FY22 and Jan” respectively and replace the third column with the name of the account. The transformation layer is often applied instantly and will be done for each row separately. So no matter how complicated your mapping becomes, Groovy should be able to manage it, I hope.
Code:
Define system properties:
//define system properties
String userName = 'administrator'
String password = 'password.epw'
String instanceUrl = 'https://**************.oraclecloud.com'
String fileName = 'BudgetHistoricalUploadFY22.csv'
String dataManagementDirectory = 'inbox/BudgetExport/'
String transformedFileName = 'HistoricalBudgetExportTranformed.csv'Login and copy file from DM directory to the Inbox/Outbox:
//Define EPM Automate
EpmAutomate automate = getEpmAutomate()
//Login to EPM - Stop the process if failed
EpmAutomateStatus loginStatus = automate.execute('login', userName , password , instanceUrl)
//Copy the file from DM directory to Inbox/Outbox directory
EpmAutomateStatus copyFileFromDataManagementToInboxOutbox = automate.execute('copyFileFromInstance', "$dataManagementDirectory$fileName", userName, password, instanceUrl, fileName);Transform the file:
//Initiate file transformation
//Read the file copied to inbox/outbox explorer, mapping indicated the column index and its required value
Map<Integer, List<String>> mapping = [1 : 'Final', 2 : ["FY21", "Jan"] , 3: "AC_Units" ] as Map<Integer, List<String> >
//create a csvWriter with Tranformed File Name
csvWriter(transformedFileName).withCloseable() { outputFileRows ->
//Iterate through uploaded file which is copied to Inbox/outbox explorer
csvIterator(fileName).withCloseable() { inputFileRows ->
inputFileRows.each { inputFileRow ->
//generate transformed row and write it to outputFile
String[] transformedRow = (inputFileRow as List<String>).indexed().collect { k,v -> mapping[k] ? mapping[k] : v }.flatten() as String[]
outputFileRows.writeNext(transformedRow)
}
}
}Copy file back to DM Directory and Logout:
//Copy tranformed file back to DataManagement Directory
EpmAutomateStatus copyFileFromInboxOutboxToDataManagement = automate.execute('copyFileFromInstance', transformedFileName, userName, password, instanceUrl, "$dataManagementDirectory$transformedFileName");
//Logout
EpmAutomateStatus logoutStatus = automate.execute('logout'); Execution Log:
Uploaded file in the Data Management Directory:
File Contents before Transformation:
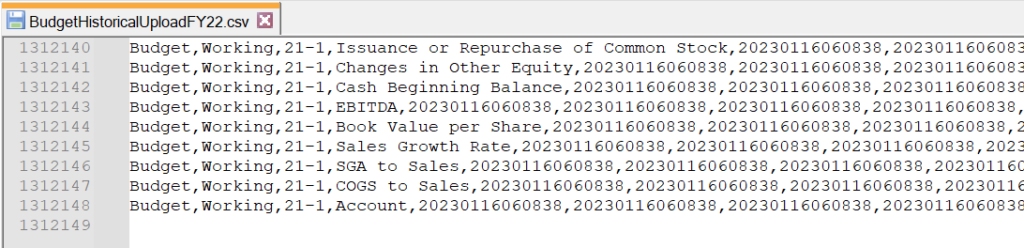
File contents after transformation:
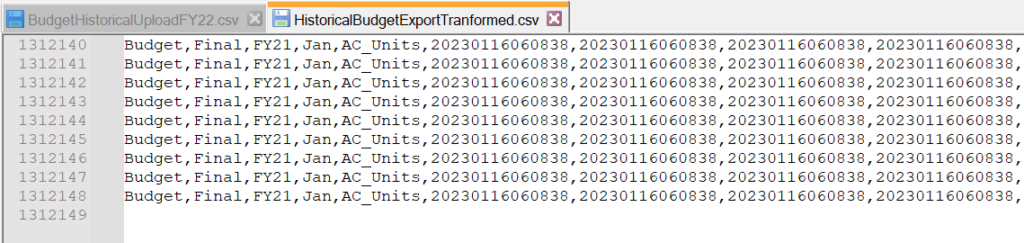
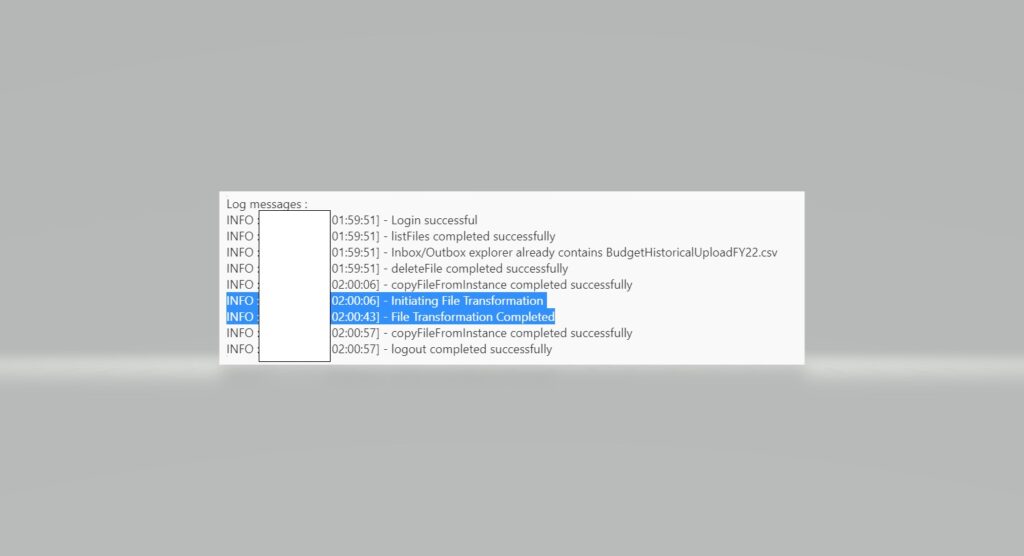
Job Console Log:
The code mentioned above doesn’t have all the components, I am handling more exceptions in my final code.
Conclusion:
This could be one of the best ways to process a large file if you frequently need to do so but don’t need to use DM features like drill back and other options. An incredible start is that the performance is really good. I really hope Oracle makes the DM files accessible via CSV Iterator so we can stop copying files back and forth. I hope that this information is useful.